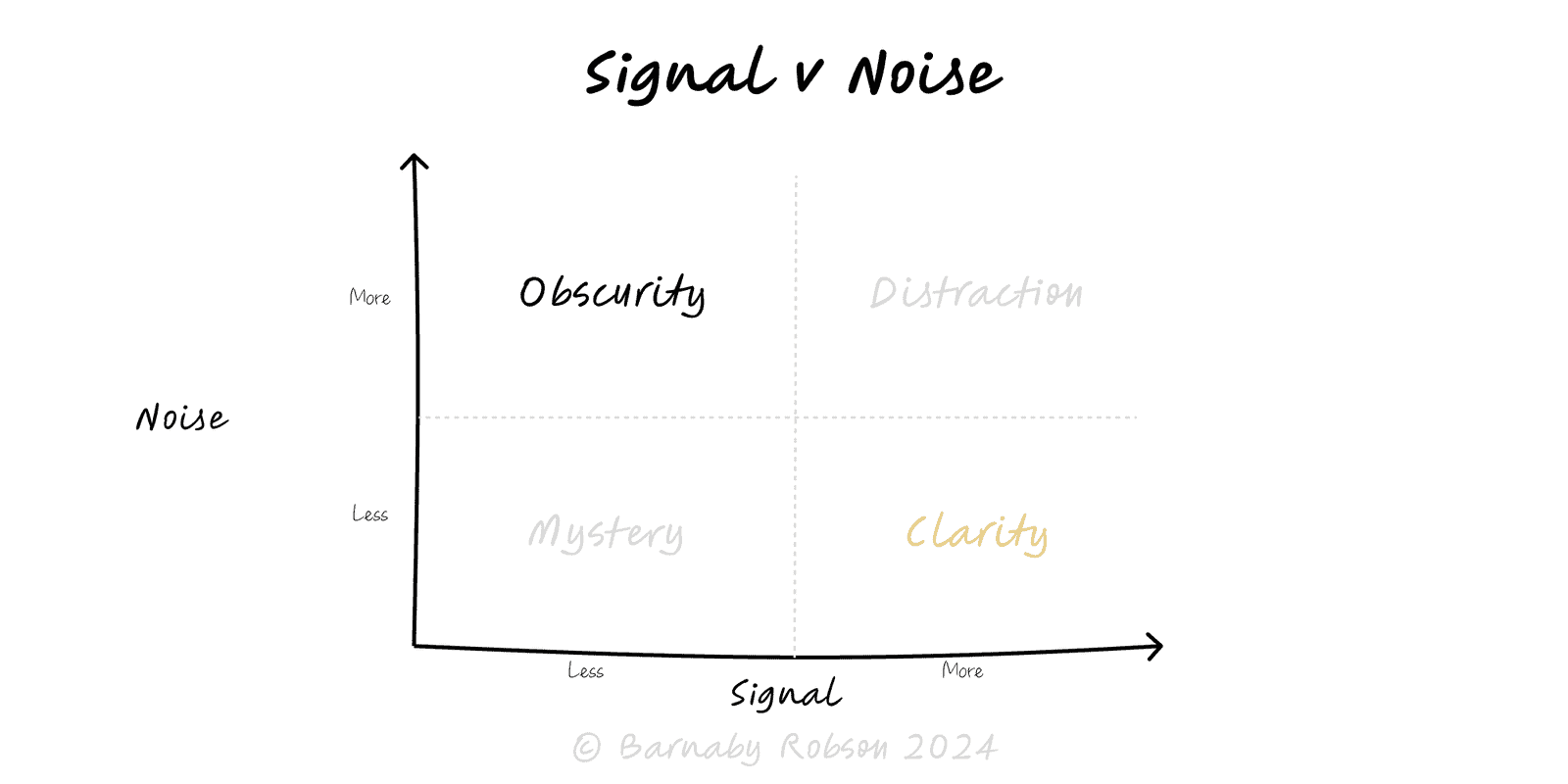
Signal – consistent pattern caused by a mechanism (trend, seasonality, causal impact).
Noise – random/unsystematic variation from sampling, timing, or measurement error.
Signal-to-noise ratio (SNR) – strength of effect vs variance; low SNR needs more data or stronger designs.
Smoothing/aggregation – moving averages, EWMA, weekly cohorts reduce noise to reveal trend.
Control limits – define expected bounds (e.g. ±3σ). Points outside likely indicate signal.
Bias–variance trade-off – more smoothing reduces variance but can hide real changes (lag).
Multiple comparisons – many metrics/tests inflate false positives; control with pre-specification or correction.