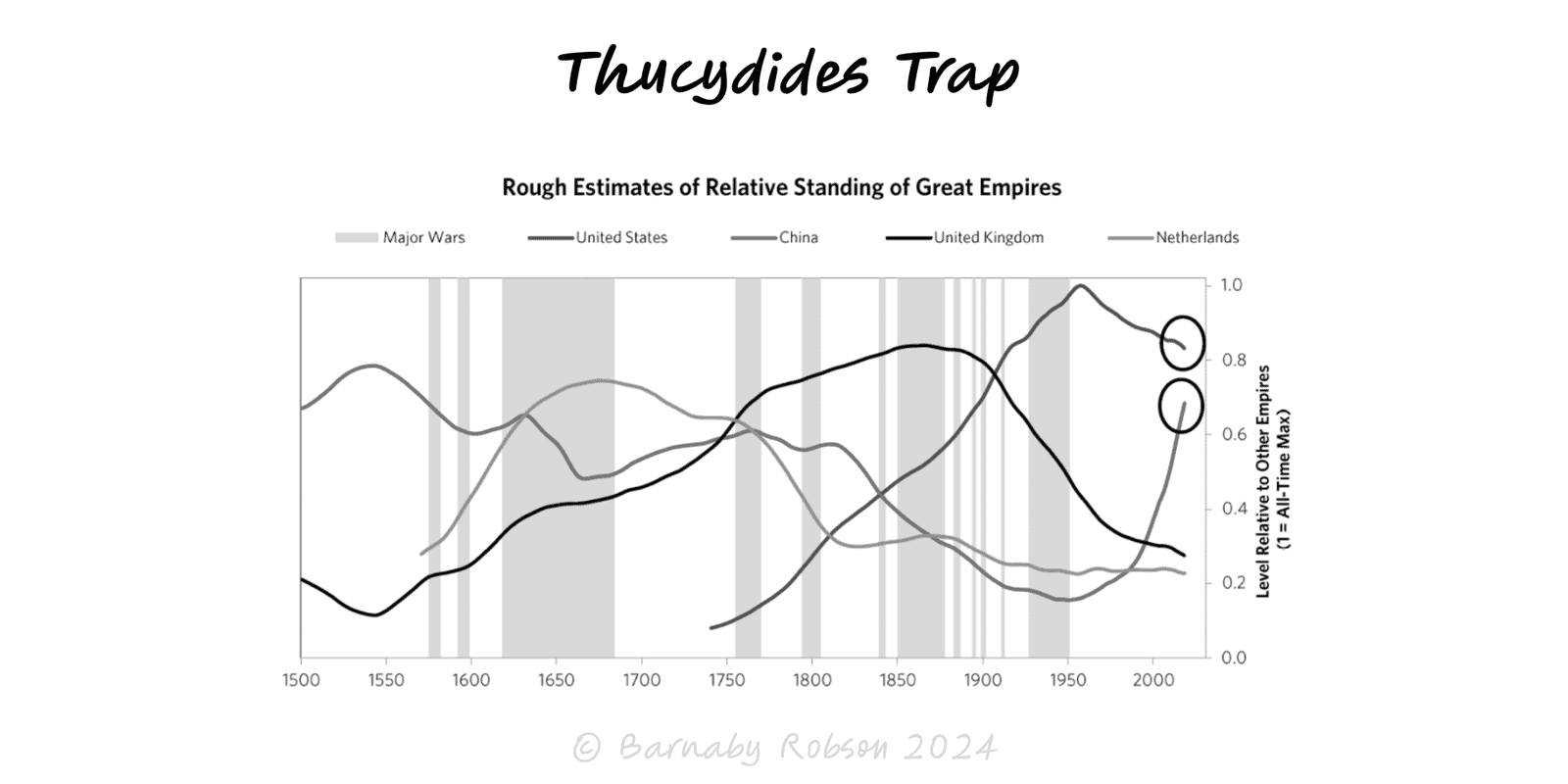
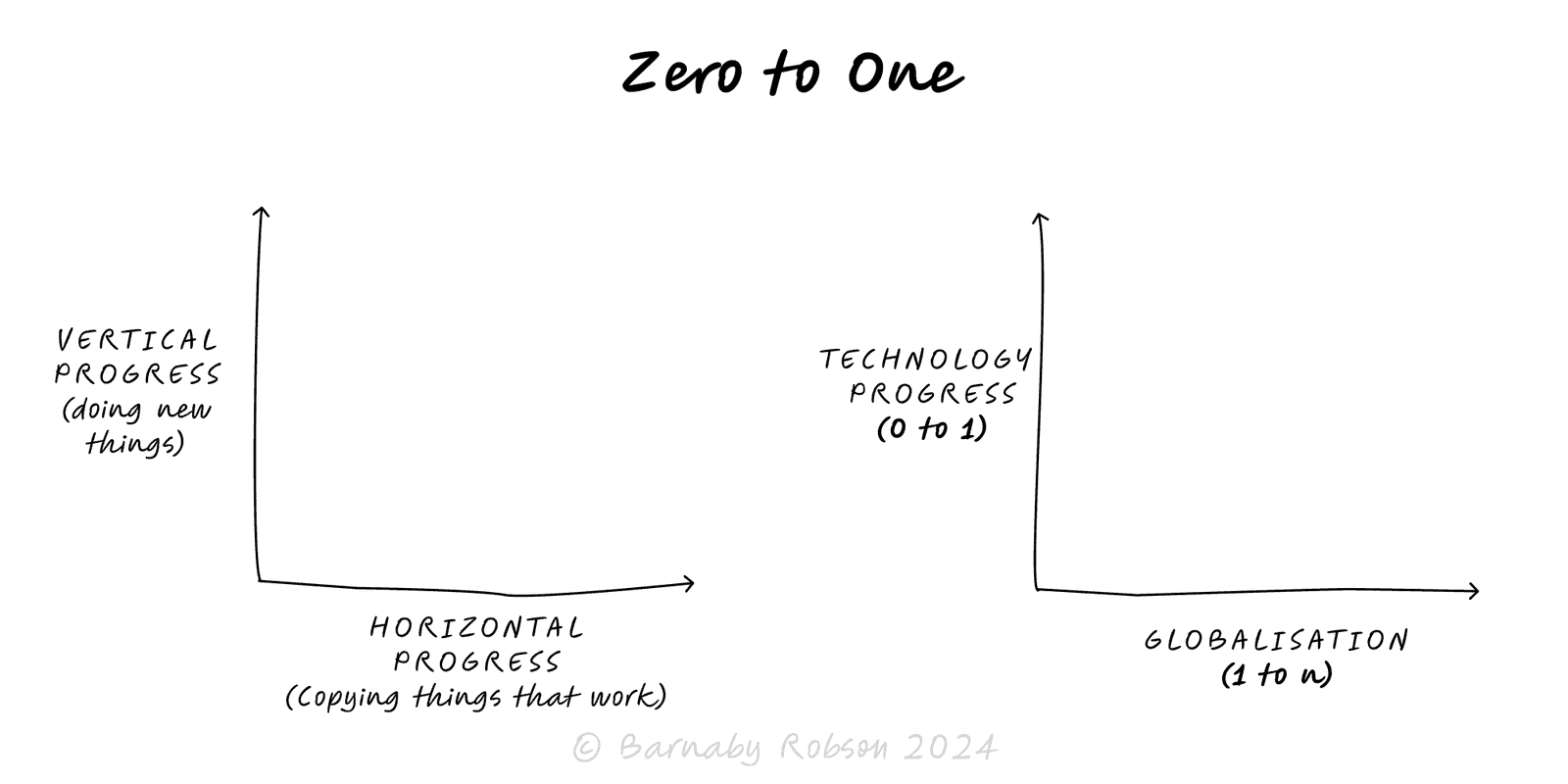
Redundancy
Add independent alternatives so one failure doesn’t stop the outcome; test failover so the backup isn’t imaginary.
Author
Reliability engineering & safety science (von Neumann, Shannon; modern SRE and business continuity practice)
Model type