
Introduction
I recently listened to five podcasts featuring: Satya Nadella, Jensen Huang, Bill Gurley, Brad Gerstner, Chetan Puttagunta, Dylan Patel, on the future of AI. Links to these at the bottom.
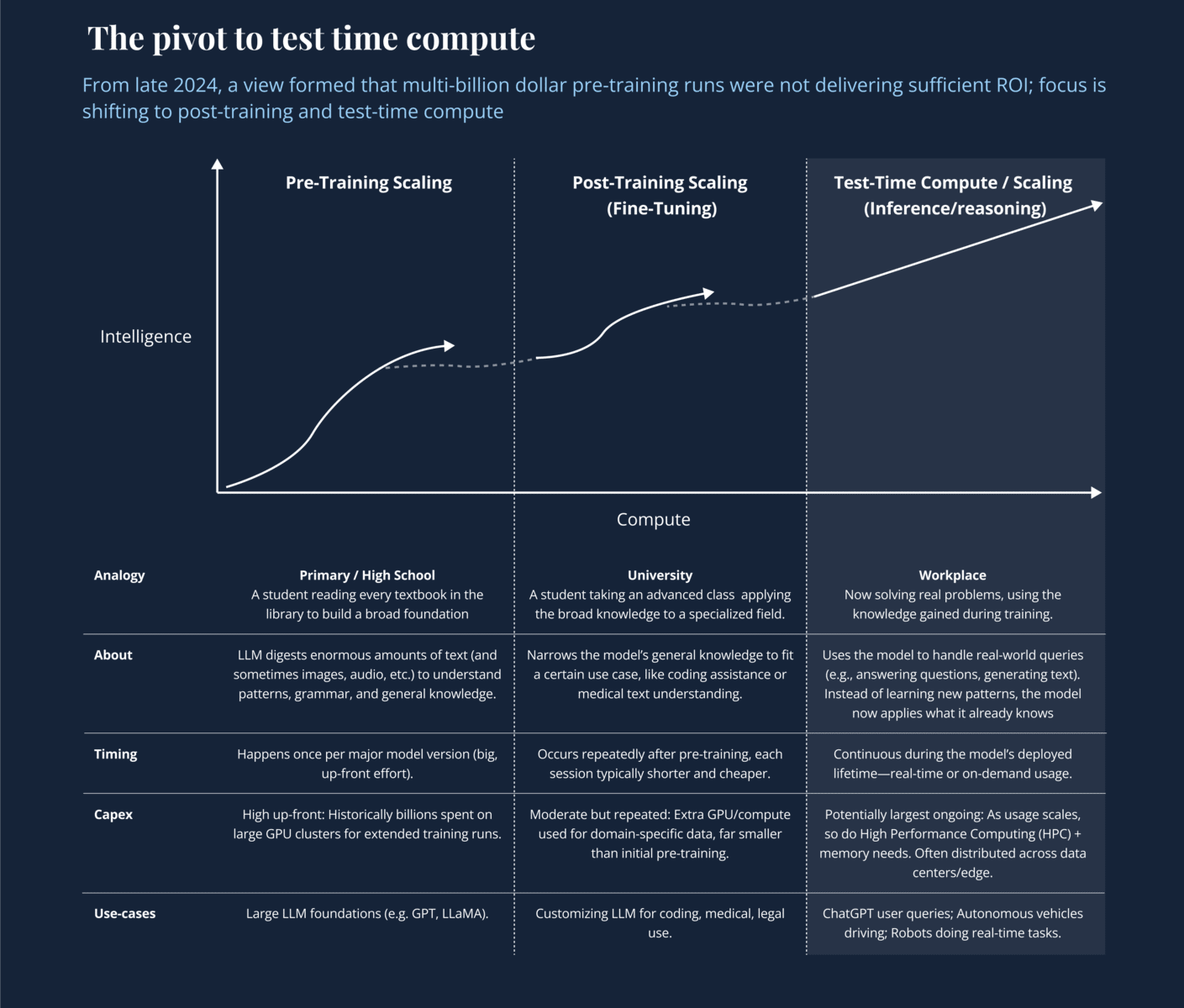
The big takeaway? AI is shifting beyond giant pre-training runs. Instead, there’s a new focus on post-training (fine-tuning) and test-time (agentic) compute, which is already reshaping where the money flows and how smaller teams can compete.
Here are the eight key themes they covered:
- Are Large Labs Hitting Pre-Training Limits?
- The Rise of Test-Time Compute & Reasoning
- Emergence of Small, Capital-Efficient AI Teams
- Open Source vs. Proprietary Frontier Models
- Cloud & Data Center Architecture Changes
- ROI on AI CapEx & Hyperscaler Economics
- The Future of AGI & Goalpost Shifts
- Physical AI: Robotics, AV, and Real-World Autonomy
I’ve set out below – their views and divergences, with infographics showing how capital is evolving, why inference is taking center stage, and what it means.
1. Are Large Labs Hitting Limits on Pre-Training at Scale?
Key Question
Have the “scaling laws” that drove major breakthroughs in LLMs (via bigger clusters and more text data) begun to plateau?
Views & Divergences
- Satya Nadella / Microsoft
- Recognizes a “plateau” in brute-force pre-training. Microsoft sees a shift toward inference-time / agentic compute (e.g., ChatGPT, co-pilots) that better aligns costs with revenue.
- However, still open to new breakthroughs if synthetic data or new model architectures appear.
- Chetan Puttagunta (Benchmark)
- Yes, for now. Scaling pre-training is stalling; synthetic data alone hasn’t boosted model performance enough. This pause lets small teams catch up via targeted fine-tuning.
- Modest Proposal (Public Investor)
- Agrees there’s a data wall: big-lab plans for $50–100B clusters are on hold without evidence that brute force leads to AGI.
- Warns: a “synthetic data unlock” could rekindle pre-training mania, but near-term, big training expansions are under scrutiny.
- Jensen Huang (NVIDIA)
- Primarily emphasizes how pre-training + post-training still need HPC. He hasn’t declared an end to scaling laws but acknowledges a pivot: labs focus on specialized tasks, more complex workflows (post-training, personalization).
- Dylan Patel (SemiAnalysis)
- Agrees we’re near a plateau for text-based LLM data. Sees the next wave of large data sets coming from video, multimodal, or sensor streams. That could reactivate big-lab spending down the road, but for now, text pre-training saturates.
Differences
- All concede some plateau in text-based pre-training.
- Jensen hints future hardware could keep pre-training relevant; Dylan adds that new data modalities (video, sensors) might prompt fresh expansions.
- Nadella / Chetan see a near-term shift to inference while labs figure out new paths.
Graphic by me.
2. The Rise of Test-Time (Inference-Time) Compute and “Reasoning” Models
Key Question
Is the future of AI improvement shifting from bigger training sets to deep reasoning at inference, with multi-step solutions?
Views & Divergences
- Chetan
- Test-time reasoning is the big new axis: “We scale intelligence on the y-axis vs. time on the x-axis.” However, not every user query needs massive multi-branch reasoning—users are impatient; cost matters.
- Modest
- Inference-time focus is financially more rational: you only spend on compute as queries arrive. More straightforward for corporate P&Ls.
- Satya (Microsoft)
- Affirm that inference usage is skyrocketing—co-pilots, AI agents, etc. Satya highlights how “co-pilot” experiences require heavy inference but can monetize well.
- Jensen
- Celebrates synergy: “Pre-training is still core, but agentic inference is a huge new vector.” Points to advanced GPU features (neural rendering, etc.) that rely on real-time inference.
- Dylan Patel
- Multimodal chain-of-thought at inference time can drastically boost HPC memory usage. For video-based or sensor-based tasks, “the compute and memory overhead dwarfs basic text inference.”
Differences
- Chetan sees a practical bottleneck on heavy test-time reasoning due to user impatience.
- Dylan specifically warns that once you add video/sensor multi-step “reasoning,” inference becomes an even bigger resource hog than many realize.

3. Emergence of Small, Capital-Efficient AI Model Teams
Key Question
Why are 2–5-person startups suddenly able to match or approach top-tier LLM performance with minimal capital?
Views & Divergences
- Chetan
- Open-source (e.g. Meta’s LLaMA) plus distillation/fine-tuning let small teams jump to near-frontier results cheaply. No multi-billion-dollar training run needed.
- Modest
- Sees this as a redistribution of AI advantage: no single “model monopoly” if open-source thrives. Good for hyperscalers who host open-source-based teams, but it disrupts closed labs.
- Satya / Microsoft
- Indirectly benefits Azure if these small model teams run inference there. Microsoft invests in big-lab pre-training but acknowledges smaller labs fill niche or domain-specific roles.
- Dylan Patel
- Highlights the cost of building smaller domain models is plummeting—particularly outside pure language tasks. “It’s easier than ever to launch a specialized robotics model or a sensor-fusion pipeline with cheap HPC.”
Differences
- Nadella invests in large-scale approach (OpenAI).
- Chetan invests in small upstarts.
- Dylan sees “hyper-specialization” as the next wave, beyond just text LLMs.
4. Open Source LLMs vs. Proprietary “Frontier” Models
Key Question
Will open-source or closed source dominate at the model layer, and does Meta’s LLaMA series tip the balance?
Views & Divergences
- Chetan
- LLaMA is a new standard foundation. Startups love it; open-source is unstoppable. Even a moderate LLaMA 4 release cements that.
- Modest
- LLaMA changed the competitive dynamics. Harder for closed labs to justify premium APIs if free or cheap models exist. Wonders if Meta might eventually close new versions.
- Satya
- Microsoft not open-sourcing GPT-4 but sees open-source as helpful if it drives Azure usage. The strategy is coexistence.
- Jensen
- NVIDIA welcomes many models (open or closed) if they demand GPUs. Gains either way.
- Dylan Patel
- Believes open-source is especially strong for non-text tasks and “multimodal expansions.” Over time, people might adopt open, extensible frameworks for images, video, sensor data, not just chat.
Differences
- All see open-source as a major force. Debate: whether big labs can still charge top dollar for “frontier” closed models (e.g., GPT-5 or Claude Next) if open solutions are near parity.
5. Cloud & Data Center Architecture Amid the “Compute Shift”
Key Question
How might data center design and cloud rollout change if training superclusters are less vital, but agentic inference is huge and often “bursty”?
Views & Divergences
- Satya / Microsoft
- Azure is well-positioned for distributed, multi-tenant inference. Believes “AI factories” must handle real-time workloads, not just big training lumps.
- Chetan
- Large enterprises can reuse on-prem GPU clusters for inference, potentially skipping big cloud bills. So, data center expansions might revolve around “mid-sized HPC” for constant usage, not one giant cluster.
- Modest
- Expects many smaller data centers or edge HPC sites, especially for agentic AI with real-time demands. Optical networking, power constraints, and latency design are underappreciated.
- Jensen
- Pitches next-gen GPU solutions (Blackwell) for flexible re-purposing— from training to partial post-training to inference. Large-lab or enterprise “fluid HPC.”
- Dylan Patel
- Video and sensor data for industrial or robotics means big bandwidth + HPC memory + possibly local edge solutions. The data center “one supercluster” model is less suitable for real-time sensor/robot tasks.
Differences
- Everyone sees distributed HPC as the future. They differ on how quickly or how heavily it’ll shift from central to edge or on-prem usage.
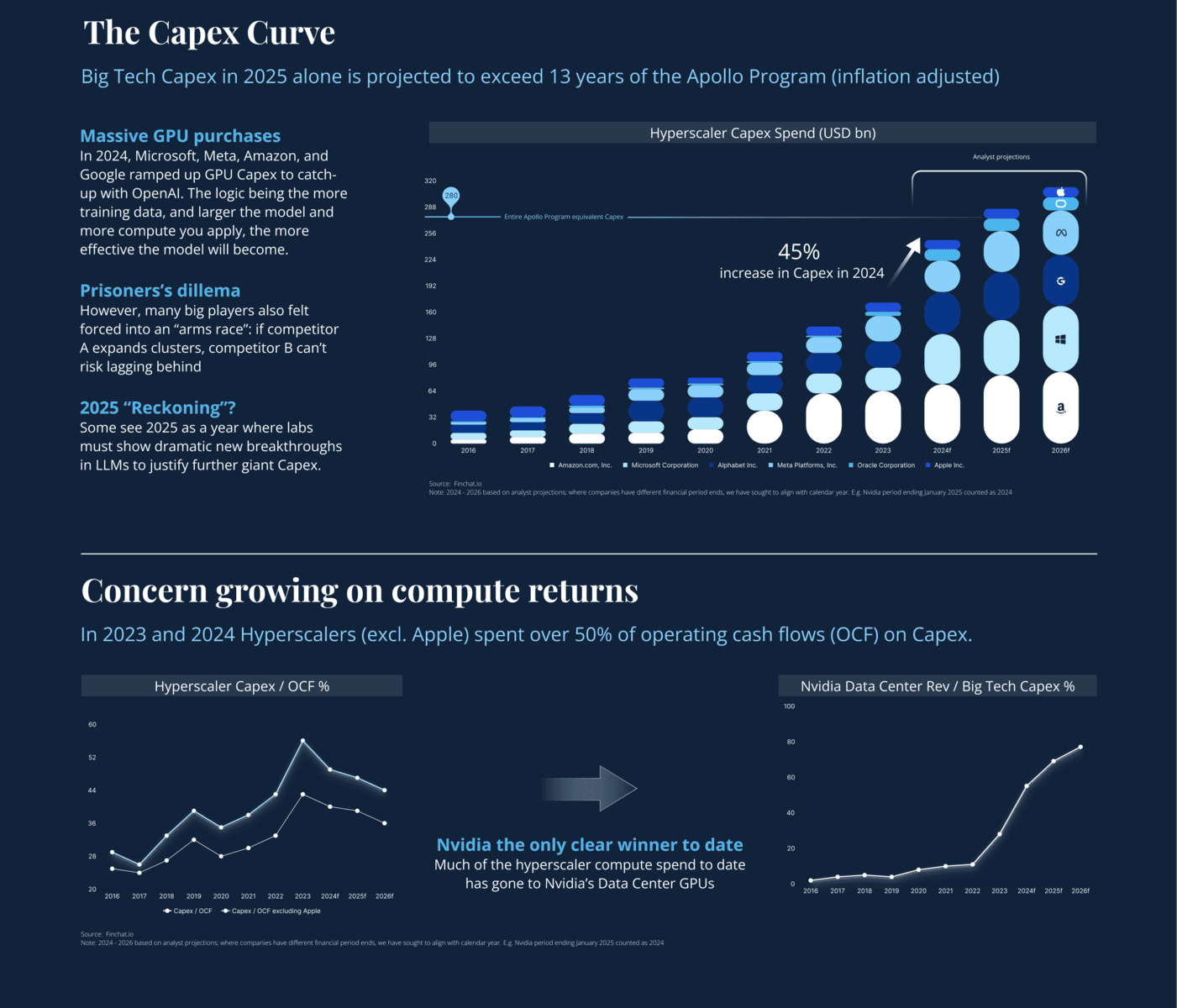
6. The ROI on AI CapEx & Hyperscaler Economics
Key Question
Have concerns around massive AI spend been eased by the test-time pivot, or might labs still chase big training leaps?
Views & Divergences
- Satya
- Now that AI usage is tied to inference, revenue accrual is clearer. However, new bigger pre-training runs (GPT-5, etc.) remain possible if breakthroughs appear.
- Modest
- Aligning costs with usage is a relief for investors. But warns that if labs find “the next big data unlock,” we might see multi-year, multi-billion-dollar “moonshots” again.
- Chetan
- Believes more stable model layers help build sustainable software companies. Sees test-time compute overshadowing training in total cost for widely adopted AI apps.
- Dylan Patel
- Notes that if multimodal data (video, sensors) becomes mainstream, overall AI CapEx might still balloon—just less on text pre-training, more on HPC memory, edge hardware, and streaming data solutions.
Differences
- All see a more rational usage-based cost approach.
- Dylan emphasizes new data modalities might still cause overall cost expansions.
7. The Future of AGI and Superintelligence
Key Question
Will we see “AGI” soon (2025?), or are we just moving the goalposts?
Views & Divergences
- Satya
- Sees AGI close by. A fully end-to-end AI that can do major knowledge work. Also envisions 2025 for tasks like travel booking done entirely by AI.
- Chetan
- Argues near-AGI could be here for many domains, but the label “AGI” is fluid. Real usage in enterprise is already surpassing many human tasks.
- Modest
- More skeptical. The “boiling frog” phenomenon means “AGI” might be declared but keep shifting the bar. Also notes the investor angle if labs “declare AGI,” which triggers IP or ownership clauses.
- Jensen
- Rarely addresses AGI directly, focusing on near-term HPC improvements. Believes big architectural leaps + compute can yield powerful systems, but stops short of “AGI is here.”
- Dylan Patel
- Minimal direct AGI commentary, but if new data modalities are fully leveraged, AI systems might surpass humans in non-linguistic tasks faster than expected.
Differences
- Some (Chetan, Satya) see near-AGI. Modest is cautious. Jensen sticks to hardware outlook, Dylan focuses on data expansions.
8. The Rise of Physical AI (Autonomous Vehicles, Robotics, Industrial Automation)
Key Question
How does AI’s pivot beyond text into real-world tasks—autonomous vehicles, warehouses, factory robots—reshape capital spending?
Views & Divergences
- Jensen
- Positions NVIDIA for huge “physical AI” expansions (Omniverse, robotics, AV). Sees sensor-fusion and real-time inference as a trillion-dollar robotics wave.
- Brad / Bill
- They mention Tesla FSD, robotics, or manufacturing as major “agentic” tasks that push day-to-day HPC usage—bigger than pre-training over time.
- Chetan
- Robotics/AV are large markets. They rely on domain-specific or multimodal post-training, plus massive inference at edge or on device.
- Dylan Patel
- Emphasizes that multimodal (video, sensor data) in AV/robotics dwarfs text in data volume. HPC memory and distributed compute soared in cost for real-time “physical AI.” This is a new frontier for capital outlays, potentially overshadowing pure text LLM expansions.
Differences
- Everyone sees physical AI as massive. Dylan specifically underscores video can “outstrip text by multiple factors,” reviving large HPC expansions for on-prem or edge solutions.